publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2024
-
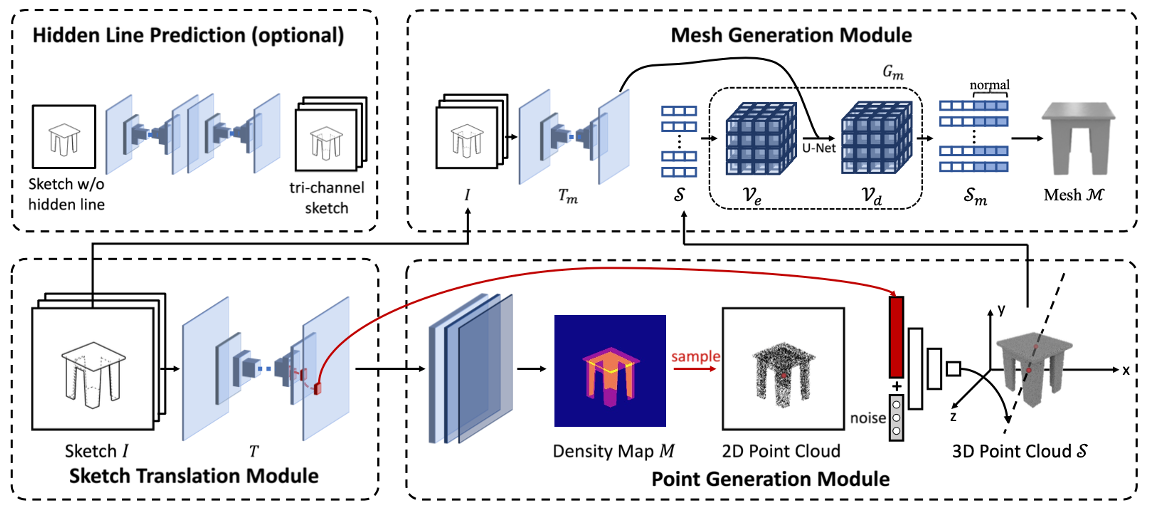 3D Reconstruction from a Single Sketch via View-dependent Depth SamplingChenjian Gao, Xilin Wang, Qian Yu, Lu Sheng, Jing Zhang, Xiaoguang Han, Yi Zhe Song, and Dong XuIEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
3D Reconstruction from a Single Sketch via View-dependent Depth SamplingChenjian Gao, Xilin Wang, Qian Yu, Lu Sheng, Jing Zhang, Xiaoguang Han, Yi Zhe Song, and Dong XuIEEE Transactions on Pattern Analysis and Machine Intelligence, 2024Reconstructing a 3D shape based on a single sketch image is challenging due to the inherent sparsity and ambiguity present in sketches. Existing methods lose fine details when extracting features to predict 3D objects from sketches. Upon analyzing the 3D-to-2D projection process, we observe that the density map, characterizing the distribution of 2D point clouds, can serve as a proxy to facilitate the reconstruction process. In this work, we propose a novel sketch-based 3D reconstruction model named
SketchSampler . It initiates the process by translating a sketch through an image translation network into a more informative 2D representation, which is then used to generate a density map. Subsequently, a two-stage probabilistic sampling process is employed to reconstruct a 3D point cloud: firstly, recovering the 2D points (i.e., thex y z -
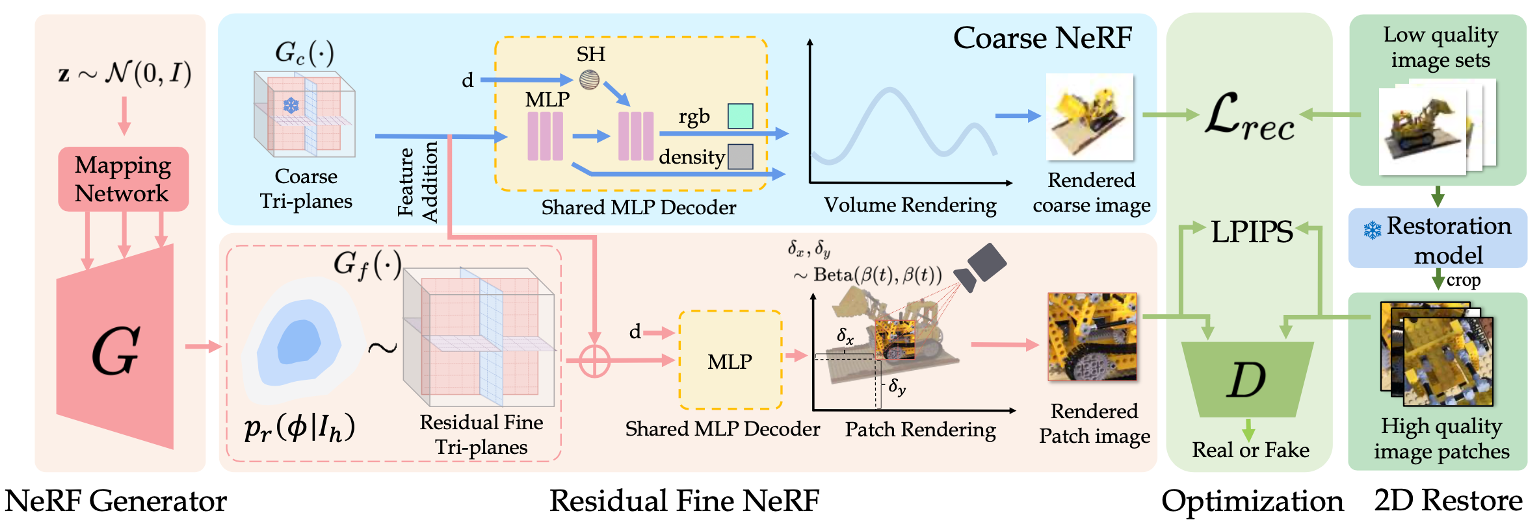 RaFE: Generative Radiance Fields RestorationZhongkai Wu, Ziyu Wan, Jing Zhang, Jing Liao, and Dong XuIn European Conference on Computer Vision, 2024
RaFE: Generative Radiance Fields RestorationZhongkai Wu, Ziyu Wan, Jing Zhang, Jing Liao, and Dong XuIn European Conference on Computer Vision, 2024NeRF (Neural Radiance Fields) has demonstrated tremendous potential in novel view synthesis and 3D reconstruction, but its performance is sensitive to input image quality, which struggles to achieve high-fidelity rendering when provided with low-quality sparse input viewpoints. Previous methods for NeRF restoration are tailored for specific degradation type, ignoring the generality of restoration. To overcome this limitation, we propose a generic radiance fields restoration pipeline, named RaFE, which applies to various types of degradations, such as low resolution, blurriness, noise, compression artifacts, or their combinations. Our approach leverages the success of off-the-shelf 2D restoration methods to recover the multi-view images individually. Instead of reconstructing a blurred NeRF by averaging inconsistencies, we introduce a novel approach using Generative Adversarial Networks (GANs) for NeRF generation to better accommodate the geometric and appearance inconsistencies present in the multi-view images. Specifically, we adopt a two-level tri-plane architecture, where the coarse level remains fixed to represent the low-quality NeRF, and a fine-level residual tri-plane to be added to the coarse level is modeled as a distribution with GAN to capture potential variations in restoration. We validate RaFE on both synthetic and real cases for various restoration tasks, demonstrating superior performance in both quantitative and qualitative evaluations, surpassing other 3D restoration methods specific to single task. Please see our project website https://zkaiwu.github.io/RaFE-Project/.
-
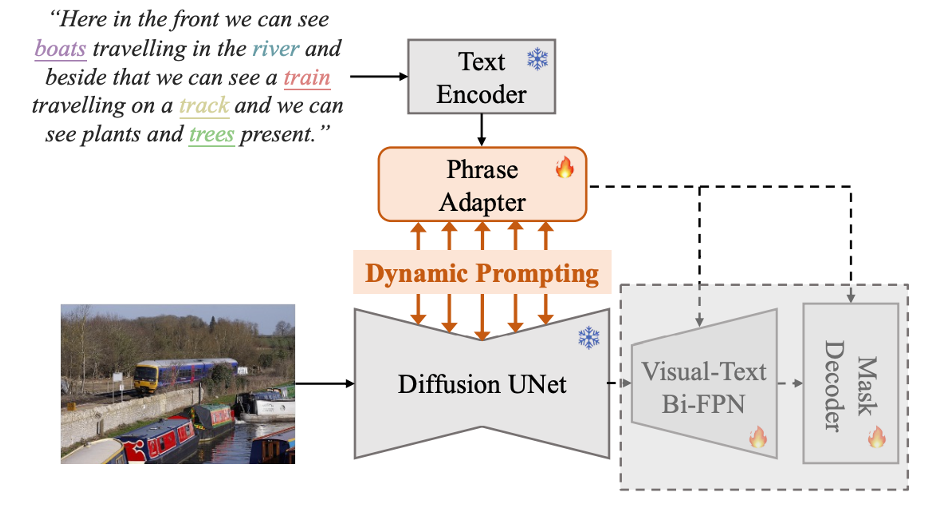 Dynamic Prompting of Frozen Text-to-Image Diffusion Models for Panoptic Narrative GroundingHongyu Li, Tianrui Hui, Zihan Ding, Jing Zhang, Bin Ma, Xiaoming Wei, Jizhong Han, and Si LiuIn Proceedings of the 32nd ACM International Conference on Multimedia (MM ’24), 2024
Dynamic Prompting of Frozen Text-to-Image Diffusion Models for Panoptic Narrative GroundingHongyu Li, Tianrui Hui, Zihan Ding, Jing Zhang, Bin Ma, Xiaoming Wei, Jizhong Han, and Si LiuIn Proceedings of the 32nd ACM International Conference on Multimedia (MM ’24), 2024Panoptic narrative grounding (PNG), whose core target is fine-grained image-text alignment, requires a panoptic segmentation of referred objects given a narrative caption. Previous discriminative methods achieve only weak or coarse-grained alignment by panoptic segmentation pretraining or CLIP model adaptation. Given the recent progress of text-to-image Diffusion models, several works have shown their capability to achieve fine-grained image-text alignment through cross-attention maps and improved general segmentation performance. However, the direct use of phrase features as static prompts to apply frozen Diffusion models to the PNG task still suffers from a large task gap and insufficient vision-language interaction, yielding inferior performance. Therefore, we propose an Extractive-Injective Phrase Adapter (EIPA) bypass within the Diffusion UNet to dynamically update phrase prompts with image features and inject the multimodal cues back, which leverages the fine-grained image-text alignment capability of Diffusion models more sufficiently. In addition, we also design a Multi-Level Mutual Aggregation (MLMA) module to reciprocally fuse multi-level image and phrase features for segmentation refinement. Extensive experiments on the PNG benchmark show that our method achieves new state-of-the-art performance.
-
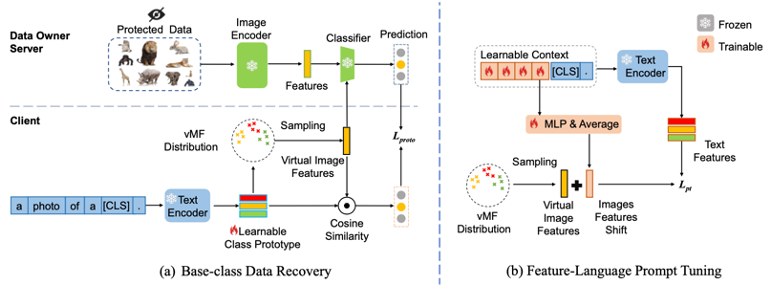 Data-Free Generalized Zero-Shot LearningBowen Tang, Jing Zhang, Long Yan, Qian Yu, Lu Sheng, and Dong XuIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024
Data-Free Generalized Zero-Shot LearningBowen Tang, Jing Zhang, Long Yan, Qian Yu, Lu Sheng, and Dong XuIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024Deep learning models have the ability to extract rich knowledge from large-scale datasets. However, the sharing of data has become increasingly challenging due to concerns regarding data copyright and privacy. Consequently, this hampers the effective transfer of knowledge from existing data to novel downstream tasks and concepts. Zero-shot learning (ZSL) approaches aim to recognize new classes by transferring semantic knowledge learned from base classes. However, traditional generative ZSL methods often require access to real images from base classes and rely on manually annotated attributes, which presents challenges in terms of data restrictions and model scalability. To this end, this paper tackles a challenging and practical problem dubbed as data-free zero-shot learning (DFZSL), where only the CLIP-based base classes data pre-trained classifier is available for zero-shot classification. Specifically, we propose a generic framework for DFZSL, which consists of three main components. Firstly, to recover the virtual features of the base data, we model the CLIP features of base class images as samples from a von Mises-Fisher (vMF) distribution based on the pre-trained classifier. Secondly, we leverage the text features of CLIP as low-cost semantic information and propose a feature-language prompt tuning (FLPT) method to further align the virtual image features and textual features. Thirdly, we train a conditional generative model using the well-aligned virtual image features and corresponding semantic text features, enabling the generation of new classes features and achieve better zero-shot generalization. Our framework has been evaluated on five commonly used benchmarks for generalized ZSL, as well as 11 benchmarks for the base-to-new ZSL. The results demonstrate the superiority and effectiveness of our approach. Our code is available in https://github.com/ylong4/DFZSL.
-
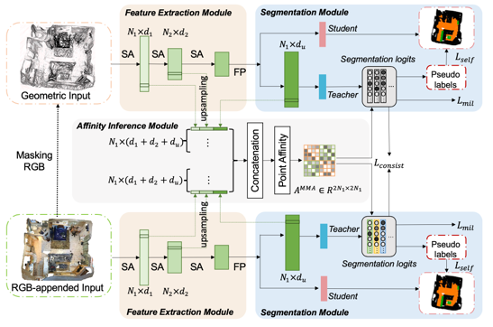 Multi-Modality Affinity Inference for Weakly Supervised 3D Semantic SegmentationXiawei Li, Qingyuan Xu, Jing Zhang, Tianyi Zhang, Qian Yu, Lu Sheng, and Dong XuIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024
Multi-Modality Affinity Inference for Weakly Supervised 3D Semantic SegmentationXiawei Li, Qingyuan Xu, Jing Zhang, Tianyi Zhang, Qian Yu, Lu Sheng, and Dong XuIn Proceedings of the AAAI Conference on Artificial Intelligence, 20243D point cloud semantic segmentation has a wide range of applications. Recently, weakly supervised point cloud segmentation methods have been proposed, aiming to alleviate the expensive and laborious manual annotation process by leveraging scene-level labels. However, these methods have not effectively exploited the rich geometric information (such as shape and scale) and appearance information (such as color and texture) present in RGB-D scans. Furthermore, current approaches fail to fully leverage the point affinity that can be inferred from the feature extraction network, which is crucial for learning from weak scene-level labels. Additionally, previous work overlooks the detrimental effects of the long-tailed distribution of point cloud data in weakly supervised 3D semantic segmentation. To this end, this paper proposes a simple yet effective scene-level weakly supervised point cloud segmentation method with a newly introduced multi-modality point affinity inference module. The point affinity proposed in this paper is characterized by features from multiple modalities (e.g., point cloud and RGB), and is further refined by normalizing the classifier weights to alleviate the detrimental effects of long-tailed distribution without the need of the prior of category distribution. Extensive experiments on the ScanNet and S3DIS benchmarks verify the effectiveness of our proposed method, which outperforms the state-of-the-art by ∼ 4% to ∼ 6% mIoU. Codes are released at https://github.com/Sunny599/AAAI24-3DWSSG-MMA.
-
 Question Calibration and Multi-Hop Modeling for Temporal Question AnsweringChao Xue, Di Liang, Pengfei Wang, and Jing ZhangIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024
Question Calibration and Multi-Hop Modeling for Temporal Question AnsweringChao Xue, Di Liang, Pengfei Wang, and Jing ZhangIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024Many models that leverage knowledge graphs (KGs) have recently demonstrated remarkable success in question answering (QA) tasks. In the real world, many facts contained in KGs are time-constrained thus temporal KGQA has received increasing attention. Despite the fruitful efforts of previous models in temporal KGQA, they still have several limitations. (I) They adopt pre-trained language models (PLMs) to obtain question representations, while PLMs tend to focus on entity information and ignore entity transfer caused by temporal constraints, and finally fail to learn specific temporal representations of entities. (II) They neither emphasize the graph structure between entities nor explicitly model the multi-hop relationship in the graph, which will make it difficult to solve complex multi-hop question answering. To alleviate this problem, we propose a novel Question Calibration and Multi-Hop Modeling (QC-MHM) approach. Specifically, We first calibrate the question representation by fusing the question and the time-constrained concepts in KG. Then, we construct the GNN layer to complete multi-hop message passing. Finally, the question representation is combined with the embedding output by the GNN to generate the final prediction. Empirical results verify that the proposed model achieves better performance than the state-of-the-art models in the benchmark dataset. Notably, the Hits@1 and Hits@10 results of QC-MHM on the CronQuestions dataset’s complex questions are absolutely improved by 5.1% and 1.2% compared to the best-performing baseline. Moreover, QC-MHM can generate interpretable and trustworthy predictions.
-
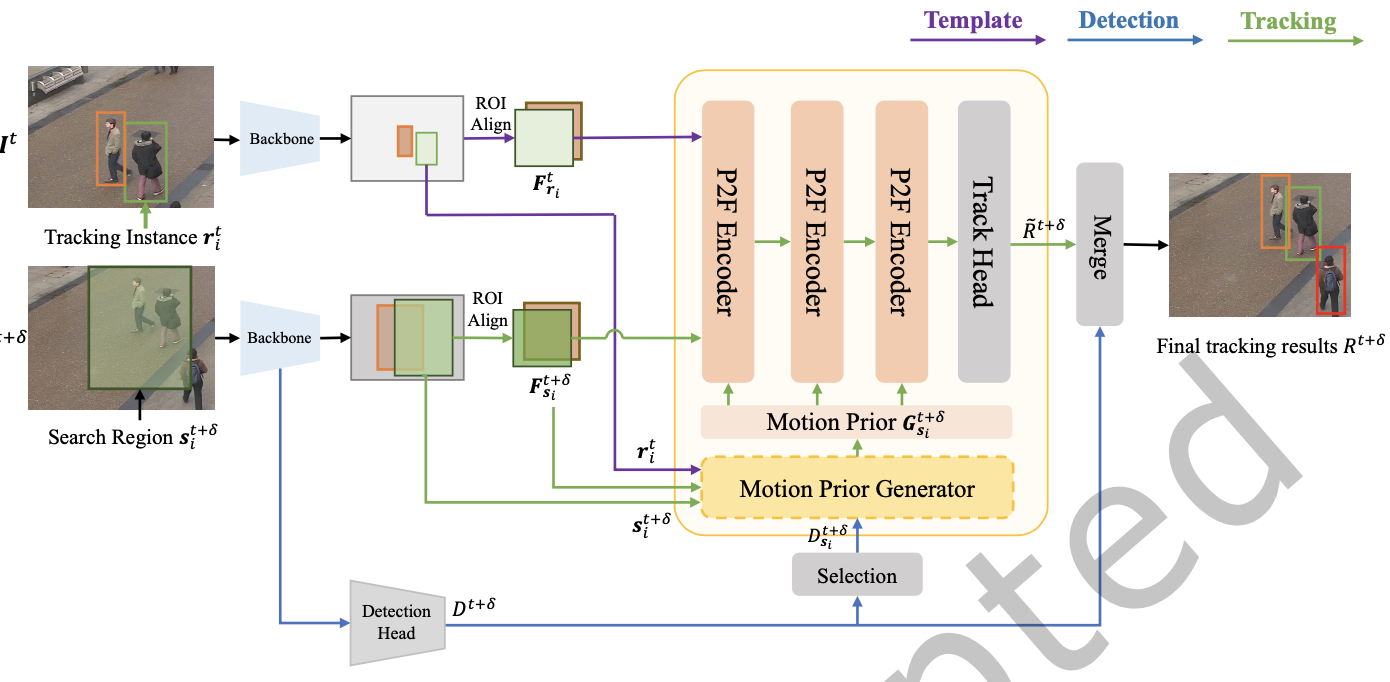 P2FTrack: Multi-object tracking with motion Prior and Feature PosteriorHong Zhang, Jiaxu Wan, Jing Zhang, Ding Yuan, XuLiang Li, and Yifan YangACM Transactions on Multimedia Computing, Communications and Applications, Oct 2024
P2FTrack: Multi-object tracking with motion Prior and Feature PosteriorHong Zhang, Jiaxu Wan, Jing Zhang, Ding Yuan, XuLiang Li, and Yifan YangACM Transactions on Multimedia Computing, Communications and Applications, Oct 2024Multiple object tracking (MOT) has emerged as a crucial component of the rapidly developing computer vision. However, existing multi-object tracking methods often overlook the relationship between features and motion, hindering the ability to strike a performance balance between coupled motion and complex scenes. In this work, we propose a novel end-to-end multi-object tracking method that integrates motion and feature information. To achieve this, we introduce a motion prior generator that transforms motion information into attention masks. Additionally, we leverage prior-posterior fusion multi-head attention to combine the motion-derived priors and attention-based posteriors. Our proposed method is extensively evaluated on MOT17 and DanceTrack datasets through comprehensive experiments and ablation studies, demonstrating state-of-the-art performance in the feature-based method with reasonable speed.
-
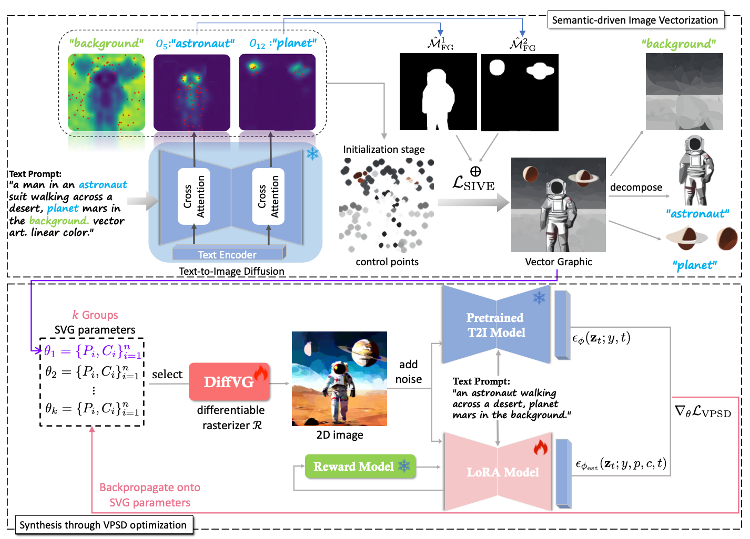 SVGDreamer: Text Guided SVG Generation with Diffusion ModelXiming Xing, Haitao Zhou, Chuang Wang, Jing Zhang, Dong Xu, and Qian YuIn IEEE Conference on Computer Vision and Pattern Recognition, Oct 2024
SVGDreamer: Text Guided SVG Generation with Diffusion ModelXiming Xing, Haitao Zhou, Chuang Wang, Jing Zhang, Dong Xu, and Qian YuIn IEEE Conference on Computer Vision and Pattern Recognition, Oct 2024Recently, text-guided scalable vector graphics (SVGs) synthesis has shown promise in domains such as iconography and sketch. However, existing text-to-SVG generation methods lack editability and struggle with visual quality and result diversity. To address these limitations, we propose a novel text-guided vector graphics synthesis method called SVGDreamer. SVGDreamer incorporates a semantic-driven image vectorization (SIVE) process that enables the decomposition of synthesis into foreground objects and background, thereby enhancing editability. Specifically, the SIVE process introduces attention-based primitive control and an attention-mask loss function for effective control and manipulation of individual elements. Additionally, we propose a Vectorized Particle-based Score Distillation (VPSD) approach to address issues of shape over-smoothing, color over-saturation, limited diversity, and slow convergence of the existing text-to-SVG generation methods by modeling SVGs as distributions of control points and colors. Furthermore, VPSD leverages a reward model to re-weight vector particles, which improves aesthetic appeal and accelerates convergence. Extensive experiments are conducted to validate the effectiveness of SVGDreamer, demonstrating its superiority over baseline methods in terms of editability, visual quality, and diversity. Project page: \hrefhttps://ximinng.github.io/SVGDreamer-project/https://ximinng.github.io/SVGDreamer-project/








2023
-
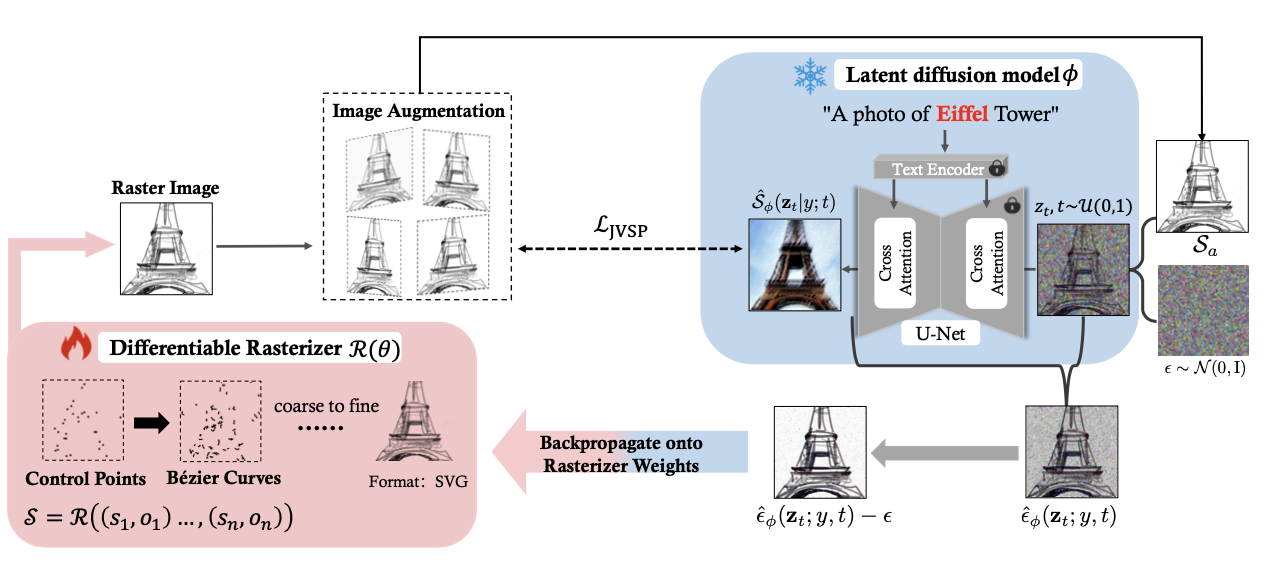 DiffSketcher: Text Guided Vector Sketch Synthesis through Latent Diffusion ModelsXiming Xing, Chuang Wang, Haitao Zhou, Jing Zhang, Qian Yu, and Dong XuAdvances in Neural Information Processing Systems, Oct 2023
DiffSketcher: Text Guided Vector Sketch Synthesis through Latent Diffusion ModelsXiming Xing, Chuang Wang, Haitao Zhou, Jing Zhang, Qian Yu, and Dong XuAdvances in Neural Information Processing Systems, Oct 2023Even though trained mainly on images, we discover that pretrained diffusion models show impressive power in guiding sketch synthesis. In this paper, we present DiffSketcher, an innovative algorithm that creates vectorized free-hand sketches using natural language input. DiffSketcher is developed based on a pre-trained text-to-image diffusion model. It performs the task by directly optimizing a set of Bézier curves with an extended version of the score distillation sampling (SDS) loss, which allows us to use a raster-level diffusion model as a prior for optimizing a parametric vectorized sketch generator. Furthermore, we explore attention maps embedded in the diffusion model for effective stroke initialization to speed up the generation process. The generated sketches demonstrate multiple levels of abstraction while maintaining recognizability, underlying structure, and essential visual details of the subject drawn. Our experiments show that DiffSketcher achieves greater quality than prior work. The code and demo of DiffSketcher can be found at https://ximinng.github.io/DiffSketcher-project/.
-
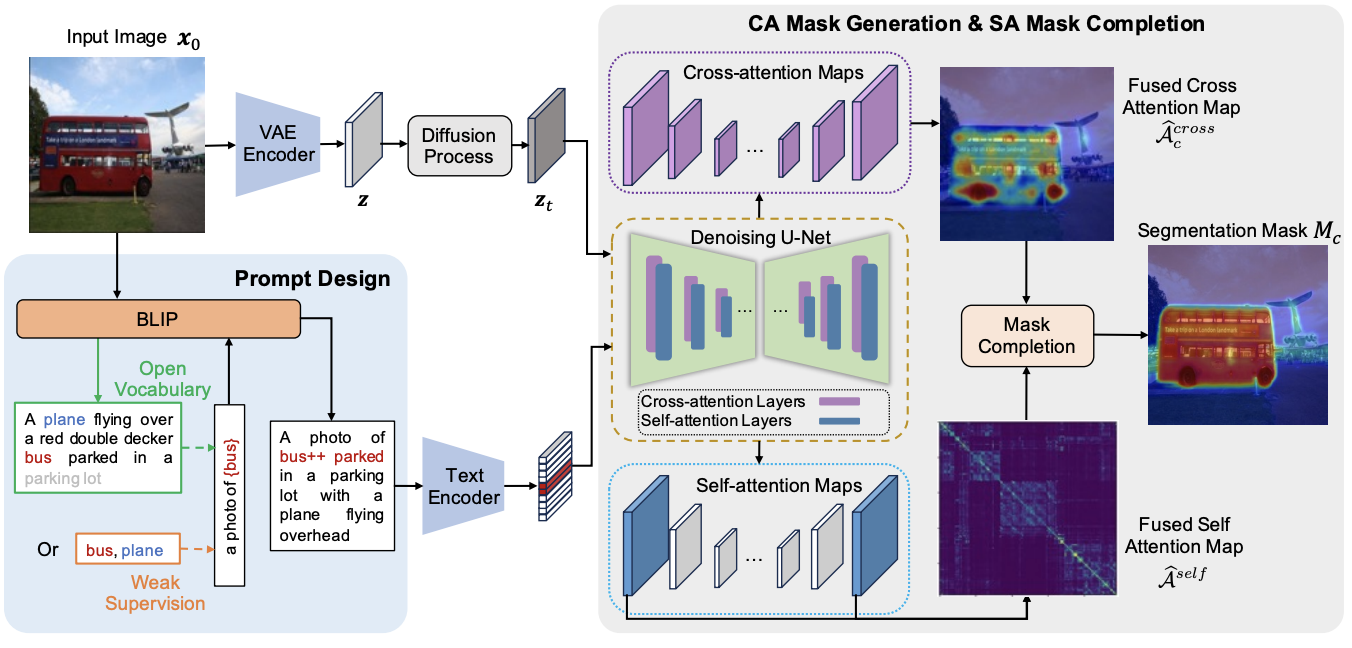 Diffusion Model is Secretly a Training-free Open Vocabulary Semantic SegmenterJinglong Wang, Xiawei Li, Jing Zhang, Qingyuan Xu, Qin Zhou, Qian Yu, Lu Sheng, and Dong XuarXiv preprint, Oct 2023
Diffusion Model is Secretly a Training-free Open Vocabulary Semantic SegmenterJinglong Wang, Xiawei Li, Jing Zhang, Qingyuan Xu, Qin Zhou, Qian Yu, Lu Sheng, and Dong XuarXiv preprint, Oct 2023Recent research has explored the utilization of pre-trained text-image discriminative models, such as CLIP, to tackle the challenges associated with open-vocabulary semantic segmentation. However, it is worth noting that the alignment process based on contrastive learning employed by these models may unintentionally result in the loss of crucial localization information and object completeness, which are essential for achieving accurate semantic segmentation. More recently, there has been an emerging interest in extending the application of diffusion models beyond text-to-image generation tasks, particularly in the domain of semantic segmentation. These approaches utilize diffusion models either for generating annotated data or for extracting features to facilitate semantic segmentation. This typically involves training segmentation models by generating a considerable amount of synthetic data or incorporating additional mask annotations. To this end, we uncover the potential of generative text-to-image conditional diffusion models as highly efficient open-vocabulary semantic segmenters, and introduce a novel training-free approach named DiffSegmenter. Specifically, by feeding an input image and candidate classes into an off-the-shelf pre-trained conditional latent diffusion model, the cross-attention maps produced by the denoising U-Net are directly used as segmentation scores, which are further refined and completed by the followed self-attention maps. Additionally, we carefully design effective textual prompts and a category filtering mechanism to further enhance the segmentation results. Extensive experiments on three benchmark datasets show that the proposed DiffSegmenter achieves impressive results for open-vocabulary semantic segmentation.
-
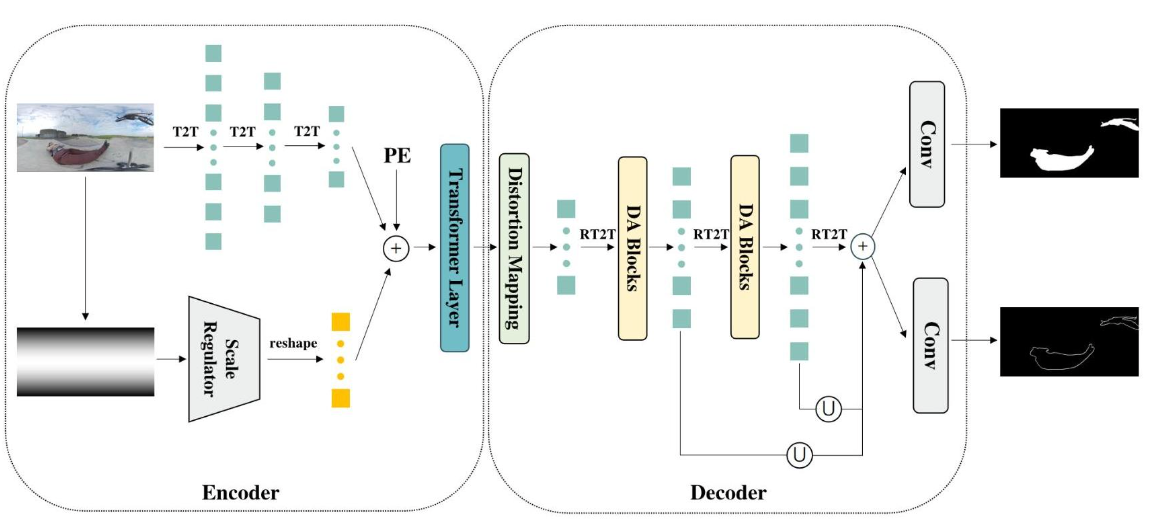 Distortion-aware Transformer in 360° Salient Object DetectionYinjie Zhao, Lichen Zhao, Qian Yu, Lu Sheng, Jing Zhang, and Dong XuIn MM 2023 - Proceedings of the 31st ACM International Conference on Multimedia, Oct 2023
Distortion-aware Transformer in 360° Salient Object DetectionYinjie Zhao, Lichen Zhao, Qian Yu, Lu Sheng, Jing Zhang, and Dong XuIn MM 2023 - Proceedings of the 31st ACM International Conference on Multimedia, Oct 2023With the emergence of VR and AR, 360° data attracts increasing attention from the computer vision and multimedia communities. Typically, 360° data is projected into 2D ERP (equirectangular projection) images for feature extraction. However, existing methods cannot handle the distortions that result from the projection, hindering the development of 360-data-based tasks. Therefore, in this paper, we propose a Transformer-based model called DATFormer to address the distortion problem. We tackle this issue from two perspectives. Firstly, we introduce two distortion-adaptive modules. The first is a Distortion Mapping Module, which guides the model to pre-adapt to distorted features globally. The second module is a Distortion-Adaptive Attention Block that reduces local distortions on multi-scale features. Secondly, to exploit the unique characteristics of 360° data, we present a learnable relation matrix and use it as part of the positional embedding to further improve performance. Extensive experiments are conducted on three public datasets, and the results show that our model outperforms existing 2D SOD (salient object detection) and 360 SOD methods. The source code is available at https://github.com/yjzhao19981027/DATFormer/.
-
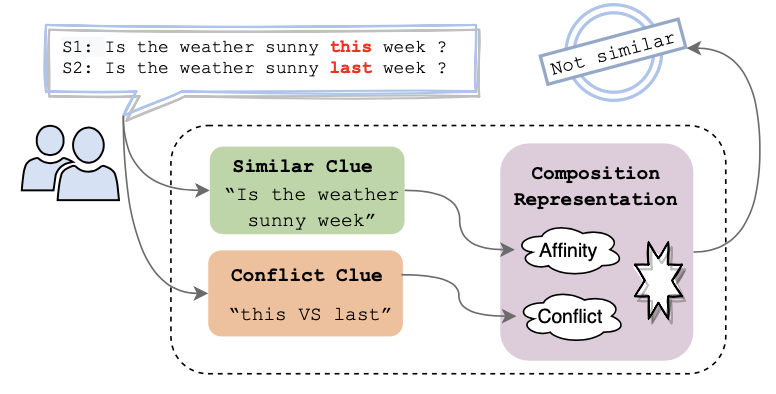 Dual Path Modeling for Semantic Matching by Perceiving Subtle ConflictsChao Xue, Di Liang, Sirui Wang, Jing Zhang, and Wei WuIn ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings, Oct 2023
Dual Path Modeling for Semantic Matching by Perceiving Subtle ConflictsChao Xue, Di Liang, Sirui Wang, Jing Zhang, and Wei WuIn ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings, Oct 2023Transformer-based pre-trained models have achieved great improvements in semantic matching. However, existing models still suffer from insufficient ability to capture subtle differences. The modification, addition and deletion of words in sentence pairs may make it difficult for the model to predict their relationship. To alleviate this problem, we propose a novel Dual Path Modeling Framework to enhance the model’s ability to perceive subtle differences in sentence pairs by separately modeling affinity and difference semantics. Based on dual-path modeling framework we design the Dual Path Modeling Network (DPM-Net) to recognize semantic relations. And we conduct extensive experiments on 10 well-studied semantic matching and robustness test datasets, and the experimental results show that our proposed method achieves consistent improvements over baselines.
-
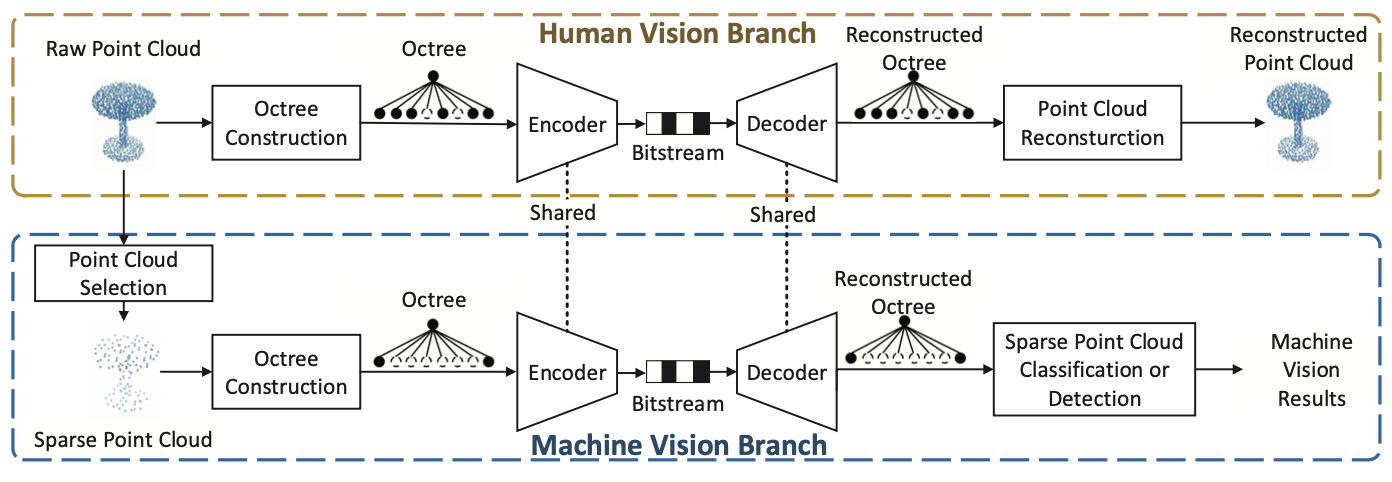 PCHM-Net : A New Point Cloud Compression Framework for Both Human Vision and Machine VisionLei Liu, Zhihao Hu, and Jing Zhang2023 IEEE International Conference on Multimedia and Expo (ICME), Oct 2023
PCHM-Net : A New Point Cloud Compression Framework for Both Human Vision and Machine VisionLei Liu, Zhihao Hu, and Jing Zhang2023 IEEE International Conference on Multimedia and Expo (ICME), Oct 2023 -
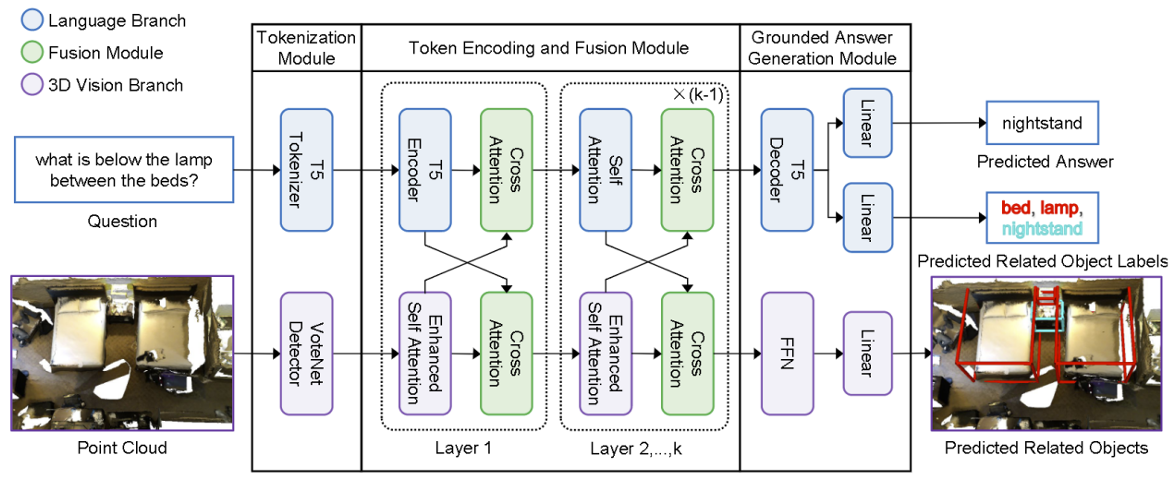 Toward Explainable 3D Grounded Visual Question Answering : A New Benchmark and Strong BaselineLichen Zhao, Daigang Cai, Jing Zhang, Lu Sheng, Dong Xu, Rui Zheng, Yinjie Zhao, Lipeng Wang, and Xibo FanIEEE Transactions on Circuits and Systems for Video Technology, Oct 2023
Toward Explainable 3D Grounded Visual Question Answering : A New Benchmark and Strong BaselineLichen Zhao, Daigang Cai, Jing Zhang, Lu Sheng, Dong Xu, Rui Zheng, Yinjie Zhao, Lipeng Wang, and Xibo FanIEEE Transactions on Circuits and Systems for Video Technology, Oct 2023






2022
-
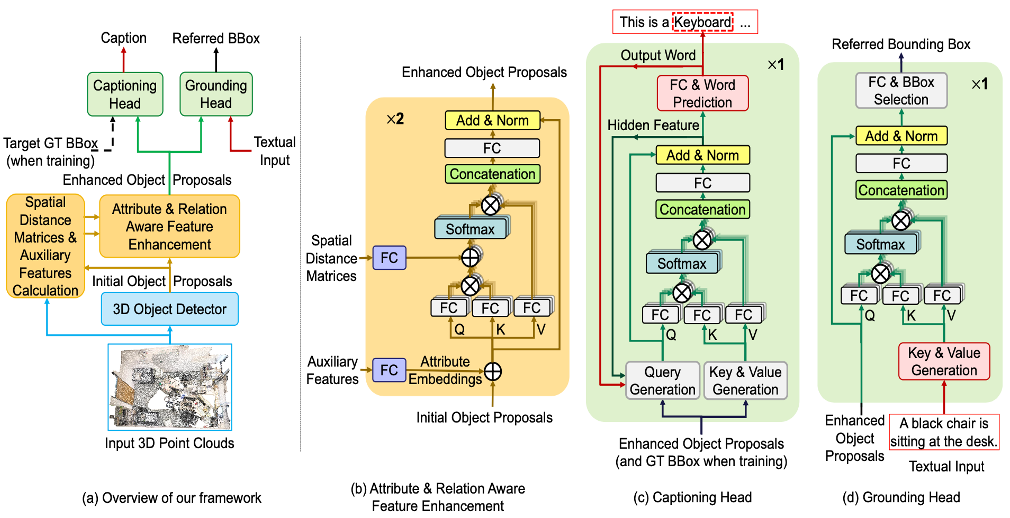 3DJCG: A Unified Framework for Joint Dense Captioning and Visual Grounding on 3D Point CloudsDaigang Cai, Lichen Zhao, Jing Zhang, Lu Sheng, and Dong XuIn IEEE Conference on Computer Vision and Pattern Recognition, Oct 2022
3DJCG: A Unified Framework for Joint Dense Captioning and Visual Grounding on 3D Point CloudsDaigang Cai, Lichen Zhao, Jing Zhang, Lu Sheng, and Dong XuIn IEEE Conference on Computer Vision and Pattern Recognition, Oct 2022Observing that the 3D captioning task and the 3D grounding task contain both shared and complementary information in nature, in this work, we propose a unified framework to jointly solve these two distinct but closely related tasks in a synergistic fashion, which consists of both shared task-agnostic modules and lightweight task-specific modules. On one hand, the shared task-agnostic modules aim to learn precise locations of objects, fine-grained attribute features to characterize different objects, and complex relations between objects, which benefit both caption-ing and visual grounding. On the other hand, by casting each of the two tasks as the proxy task of another one, the lightweight task-specific modules solve the captioning task and the grounding task respectively. Extensive experiments and ablation study on three 3D vision and language datasets demonstrate that our joint training framework achieves significant performance gains for each individual task and finally improves the state-of-the-art performance for both captioning and grounding tasks.
-
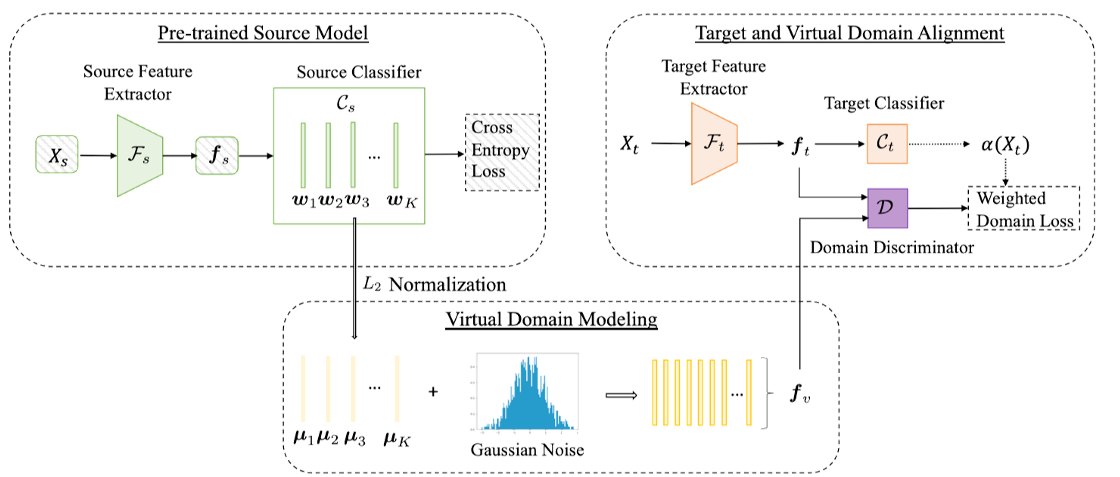 VDM-DA: Virtual Domain Modeling for Source Data-Free Domain AdaptationJiayi Tian, Jing Zhang, Wen Li, and Dong XuIEEE Transactions on Circuits and Systems for Video Technology, Oct 2022
VDM-DA: Virtual Domain Modeling for Source Data-Free Domain AdaptationJiayi Tian, Jing Zhang, Wen Li, and Dong XuIEEE Transactions on Circuits and Systems for Video Technology, Oct 2022Domain adaptation aims to leverage a label-rich domain (the source domain) to help model learning in a label-scarce domain (the target domain). Most domain adaptation methods require the co-existence of source and target domain samples to reduce the distribution mismatch. However, access to the source domain samples may not always be feasible in real-world applications due to different problems (e.g., storage, transmission, and privacy issues). In this work, we deal with the source data-free unsupervised domain adaptation problem and propose a novel approach referred to as Virtual Domain Modeling for Domain Adaptation (VDM-DA), in which the virtual domain acts as a bridge between the source and target domains. Specifically, based on the pre-trained source model, we generate the virtual domain samples by using an approximated Gaussian Mixture Model (GMM) in the feature space, such that the virtual domain maintains a similar distribution with the source domain without access to the original source data. Moreover, we also design an effective distribution alignment method to reduce the distribution divergence between the virtual domain and the target domain by gradually improving the compactness of the target domain distribution through model learning. In this way, we successfully achieve the goal of distribution alignment between the source and target domains when training deep networks without access to the source domain data. We conduct extensive experiments on four benchmark datasets for both 2D image-based and 3D point cloud-based cross-domain object recognition tasks, where the proposed method referred to as Virtual Domain Modeling for Domain Adaptation (VDM-DA) achieves the promising performance on all datasets.
-
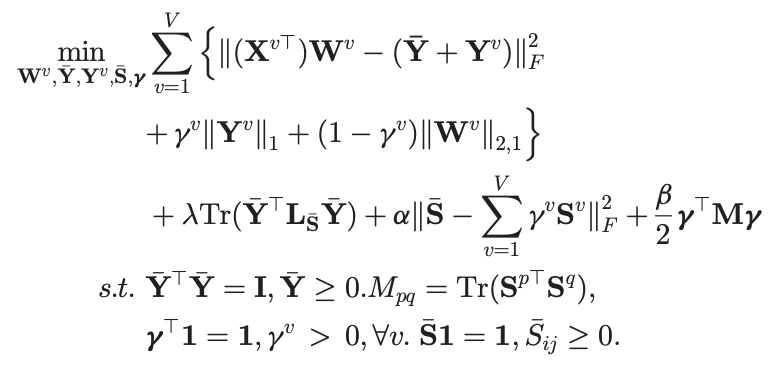 Cross-view Locality Preserved Diversity and Consensus Learning for Multi-view Unsupervised Feature SelectionChang Tang, Xiao Zheng, Xinwang Liu, Wei Zhang, Jing Zhang, Jian Xiong, and Lizhe WangIEEE Transactions on Knowledge and Data Engineering, Oct 2022
Cross-view Locality Preserved Diversity and Consensus Learning for Multi-view Unsupervised Feature SelectionChang Tang, Xiao Zheng, Xinwang Liu, Wei Zhang, Jing Zhang, Jian Xiong, and Lizhe WangIEEE Transactions on Knowledge and Data Engineering, Oct 2022Although demonstrating great success, previous multi-view unsupervised feature selection (MV-UFS) methods often construct a view-specific similarity graph and characterize the local structure of data within each single view. In such a way, the cross-view information could be ignored. In addition, they usually assume that different feature views are projected from a latent feature space while the diversity of different views cannot be fully captured. In this work, we resent a MV-UFS model via cross-view local structure preserved diversity and consensus learning, referred to as CvLP-DCL briefly. In order to exploit both the shared and distinguishing information across different views, we project each view into a label space, which consists of a consensus part and a view-specific part. Therefore, we regularize the fact that different views represent same samples. Meanwhile, a cross-view similarity graph learning term with matrix-induced regularization is embedded to preserve the local structure of data in the label space. By imposing the
l_2,1 -
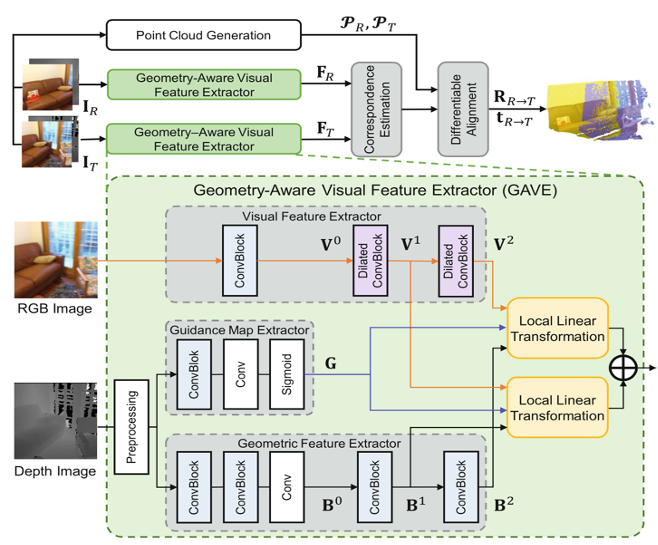 Improving RGB-D Point Cloud Registration by Learning Multi-scale Local Linear TransformationZiming Wang, Xiaoliang Huo, Zhenghao Chen, Jing Zhang, Lu Sheng, and Dong XuIn European Conference on Computer Vision, Oct 2022
Improving RGB-D Point Cloud Registration by Learning Multi-scale Local Linear TransformationZiming Wang, Xiaoliang Huo, Zhenghao Chen, Jing Zhang, Lu Sheng, and Dong XuIn European Conference on Computer Vision, Oct 2022Point cloud registration aims at estimating the geometric transformation between two point cloud scans, in which point-wise correspondence estimation is the key to its success. In addition to previous methods that seek correspondences by hand-crafted or learnt geometric features, recent point cloud registration methods have tried to apply RGB-D data to achieve more accurate correspondence. However, it is not trivial to effectively fuse the geometric and visual information from these two distinctive modalities, especially for the registration problem. In this work, we propose a new Geometry-Aware Visual Feature Extractor (GAVE) that employs multi-scale local linear transformation to progressively fuse these two modalities, where the geometric features from the depth data act as the geometry-dependent convolution kernels to transform the visual features from the RGB data. The resultant visual-geometric features are in canonical feature spaces with alleviated visual dissimilarity caused by geometric changes, by which more reliable correspondence can be achieved. The proposed GAVE module can be readily plugged into recent RGB-D point cloud registration framework. Extensive experiments on 3D Match and ScanNet demonstrate that our method outperforms the state-of-the-art point cloud registration methods even without correspondence or pose supervision. The code is available at: https://github.com/514DNA/LLT.




2021
-
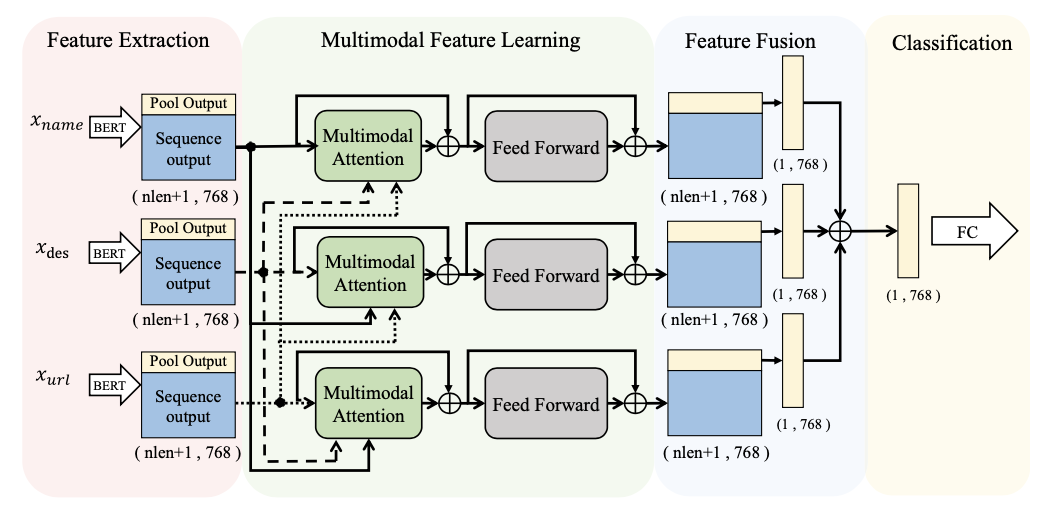 MMA-Net: A MultiModal-Attention-Based Deep Neural Network for Web Services ClassificationJing Zhang, Changran Lei, Yilong Yang, Borui Wang, and Yang ChenIn 19th International Conference on Service-Oriented Computing, ICSOC 2021, Oct 2021
MMA-Net: A MultiModal-Attention-Based Deep Neural Network for Web Services ClassificationJing Zhang, Changran Lei, Yilong Yang, Borui Wang, and Yang ChenIn 19th International Conference on Service-Oriented Computing, ICSOC 2021, Oct 2021Recently, machine learning has been widely used for services classification that plays a crucial role in services discovery, selection, and composition. The current methods mostly rely on only one data modality (e.g. services description) for web services classification but fail to fully exploit other readily available data modalities (e.g. services names, and URL). In this paper, a novel MultiModal-Attention-based deep neural network (MMA-Net) is proposed to facilitate the web services classification task via effective feature learning from multiple readily available data modalities. Specifically, a new multimodal feature learning module is introduced to achieve effective message passing and information exchanging among multiple modalities. We conduct experiments on the real-world web services dataset using various evaluation metrics, and the results show that our framework achieves the state-of-the-art results.
-
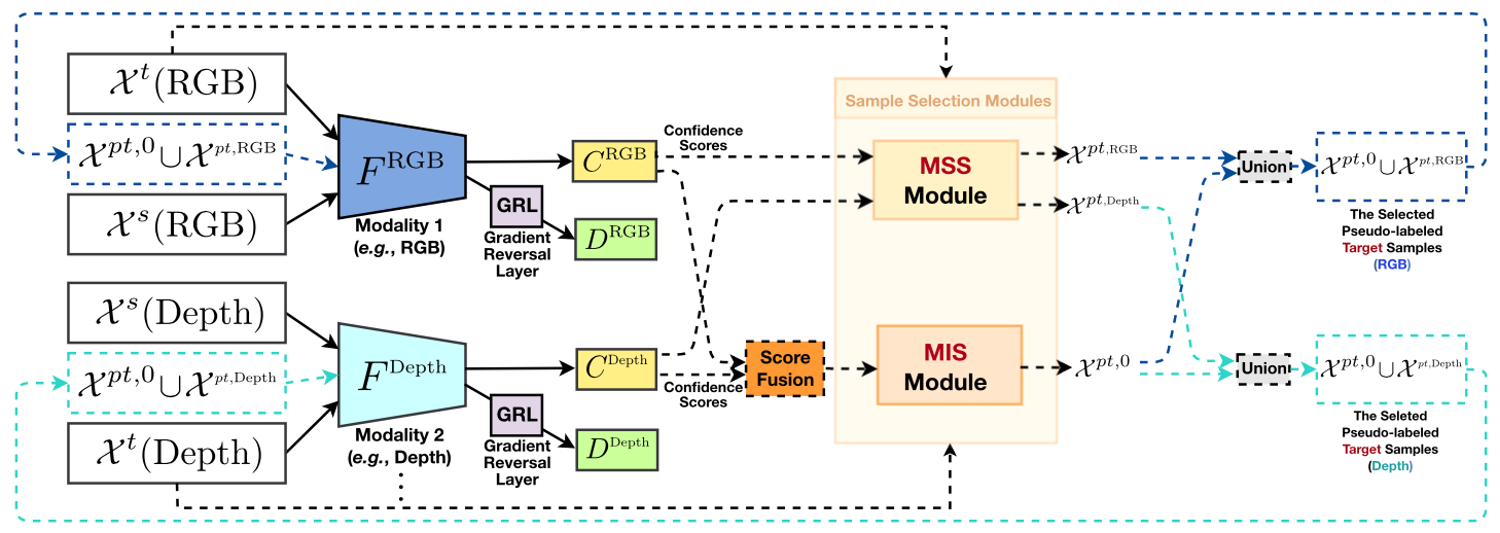 Progressive Modality Cooperation for Multi-Modality Domain AdaptationWeichen Zhang, Dong Xu, Jing Zhang, and Wanli OuyangIEEE Transactions on Image Processing, Oct 2021
Progressive Modality Cooperation for Multi-Modality Domain AdaptationWeichen Zhang, Dong Xu, Jing Zhang, and Wanli OuyangIEEE Transactions on Image Processing, Oct 2021In this work, we propose a new generic multi-modality domain adaptation framework called Progressive Modality Cooperation (PMC) to transfer the knowledge learned from the source domain to the target domain by exploiting multiple modality clues (e.g., RGB and depth) under the multi-modality domain adaptation (MMDA) and the more general multi-modality domain adaptation using privileged information (MMDA-PI) settings. Under the MMDA setting, the samples in both domains have all the modalities. Through effective collaboration among multiple modalities, the two newly proposed modules in our PMC can select the reliable pseudo-labeled target samples, which captures the modality-specific information and modality-integrated information, respectively. Under the MMDA-PI setting, some modalities are missing in the target domain. Hence, to better exploit the multi-modality data in the source domain, we further propose the PMC with privileged information (PMC-PI) method by proposing a new multi-modality data generation (MMG) network. MMG generates the missing modalities in the target domain based on the source domain data by considering both domain distribution mismatch and semantics preservation, which are respectively achieved by using adversarial learning and conditioning on weighted pseudo semantic class labels. Extensive experiments on three image datasets and eight video datasets for various multi-modality cross-domain visual recognition tasks under both MMDA and MMDA-PI settings clearly demonstrate the effectiveness of our proposed PMC framework.
-
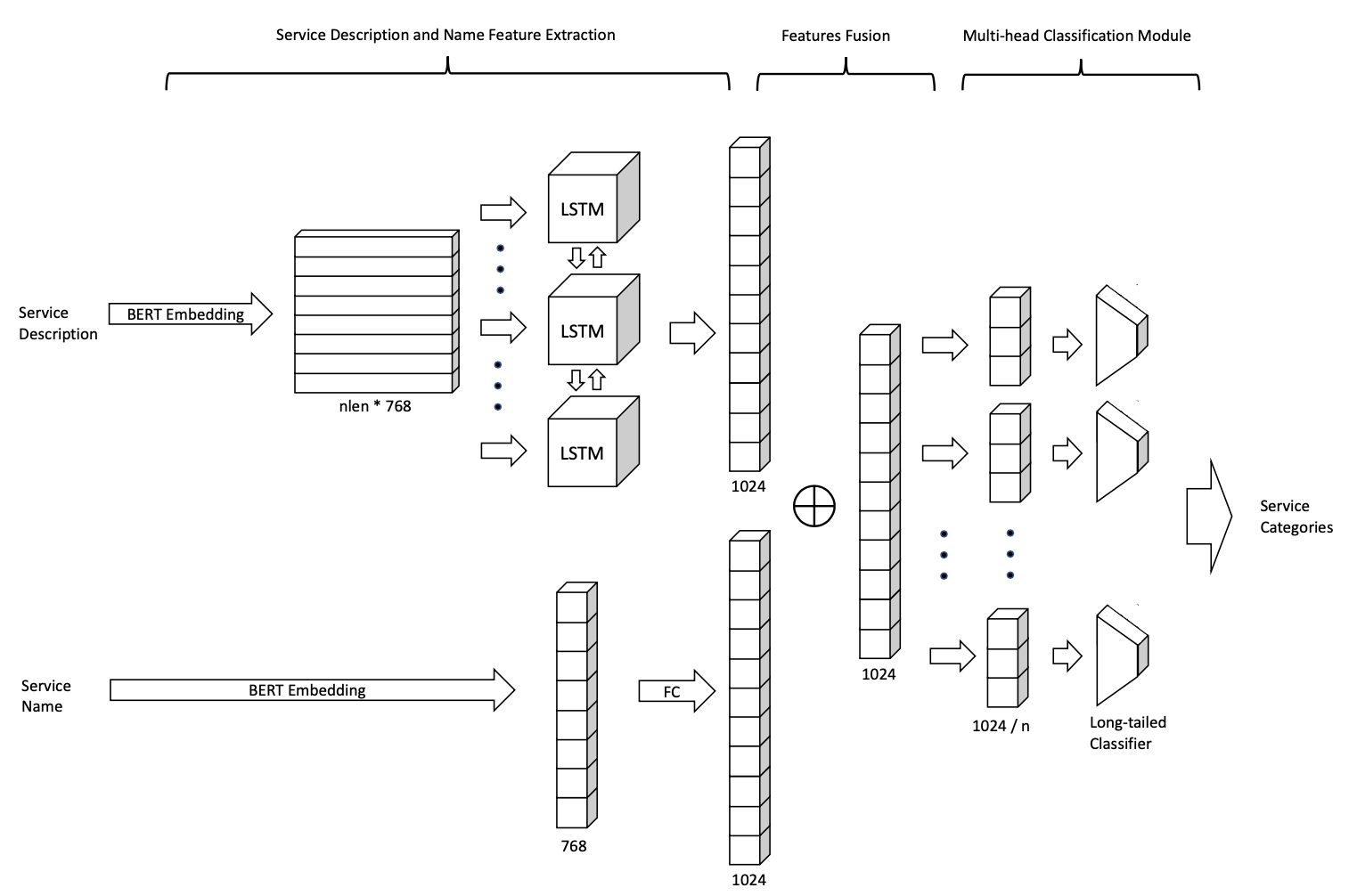 ServeNet-LT: A Normalized Multi-head Deep Neural Network for Long-tailed Web Services ClassificationJing Zhang, Yang Chen, Yilong Yang, Changran Lei, and Deqiang WangIn IEEE International Conference on Web Services, Oct 2021
ServeNet-LT: A Normalized Multi-head Deep Neural Network for Long-tailed Web Services ClassificationJing Zhang, Yang Chen, Yilong Yang, Changran Lei, and Deqiang WangIn IEEE International Conference on Web Services, Oct 2021Automatic service classification plays an important role in service discovery, selection, and composition. Recently, machine learning has been widely used in service classification. Though promising results are obtained, previous methods are merely evaluated on web services datasets with small-scale data and relatively balanced data, which limit their real-world applications. In this paper, we address the long-tailed web services classification problem with more categories and imbalanced data. Due to the long-tailed distribution of datasets, the existing machine learning and deep learning methods cannot work well. To deal with the long-tailed problem, we propose a normalized multi-head classifier learning strategy, which effectively reduces the classifier bias and benefit the generalization capacity of the extracted features. Extensive experiments are conducted on a large-scale long-tailed web services dataset, and the results show that our model outperforms the 11 compared service classification methods to a large margin.
-
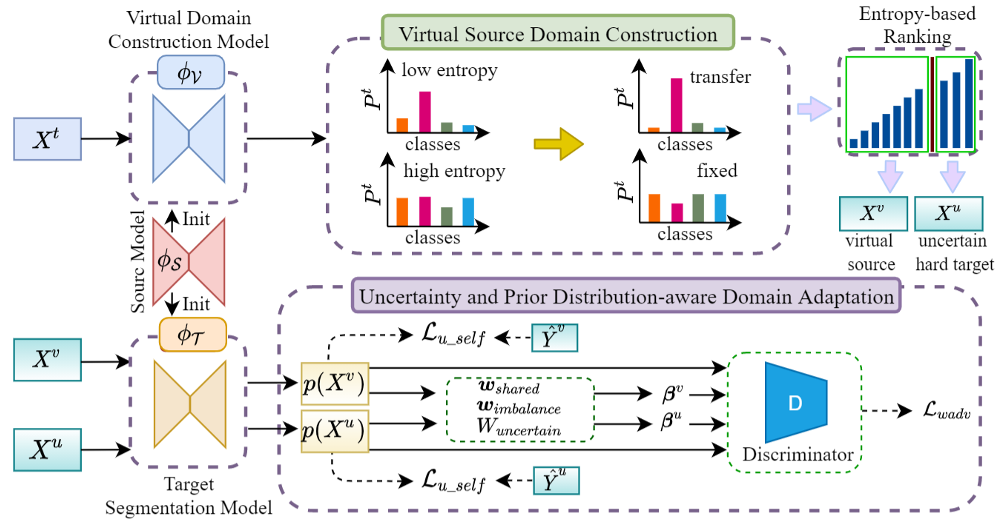 Source Data-free Unsupervised Domain Adaptation for Semantic SegmentationMucong Ye, Jing Zhang, Jinpeng Ouyang, and DIng YuanIn ACM International Conference on Multimedia, Oct 2021
Source Data-free Unsupervised Domain Adaptation for Semantic SegmentationMucong Ye, Jing Zhang, Jinpeng Ouyang, and DIng YuanIn ACM International Conference on Multimedia, Oct 2021Deep\footnote learning-based semantic segmentation methods require a huge amount of training images with pixel-level annotations. Unsupervised domain adaptation (UDA) for semantic segmentation enables transferring knowledge learned from the synthetic data (source domain) with low-cost annotations to the real images (target domain). However, current UDA methods mostly require full access to the source domain data for feasible adaptation, which limits their applications in real-world scenarios with privacy, storage, or transmission issues. To this end, this paper identifies and addresses a more practical but challenging problem of UDA for semantic segmentation, where access to the original source domain data is forbidden. In other words, only the pre-trained source model and unlabelled target domain data are available for adaptation. To tackle the problem, we propose to construct a set of source domain virtual data to mimic the source domain distribution by identifying the target domain high-confidence samples predicted by the pre-trained source model. Then by analyzing the data properties in the cross-domain semantic segmentation tasks, we propose an uncertainty and prior distribution-aware domain adaptation method to align the virtual source domain and the target domain with both adversarial learning and self-training strategies. Extensive experiments on three cross-domain semantic segmentation datasets with in-depth analyses verify the effectiveness of the proposed method.
-
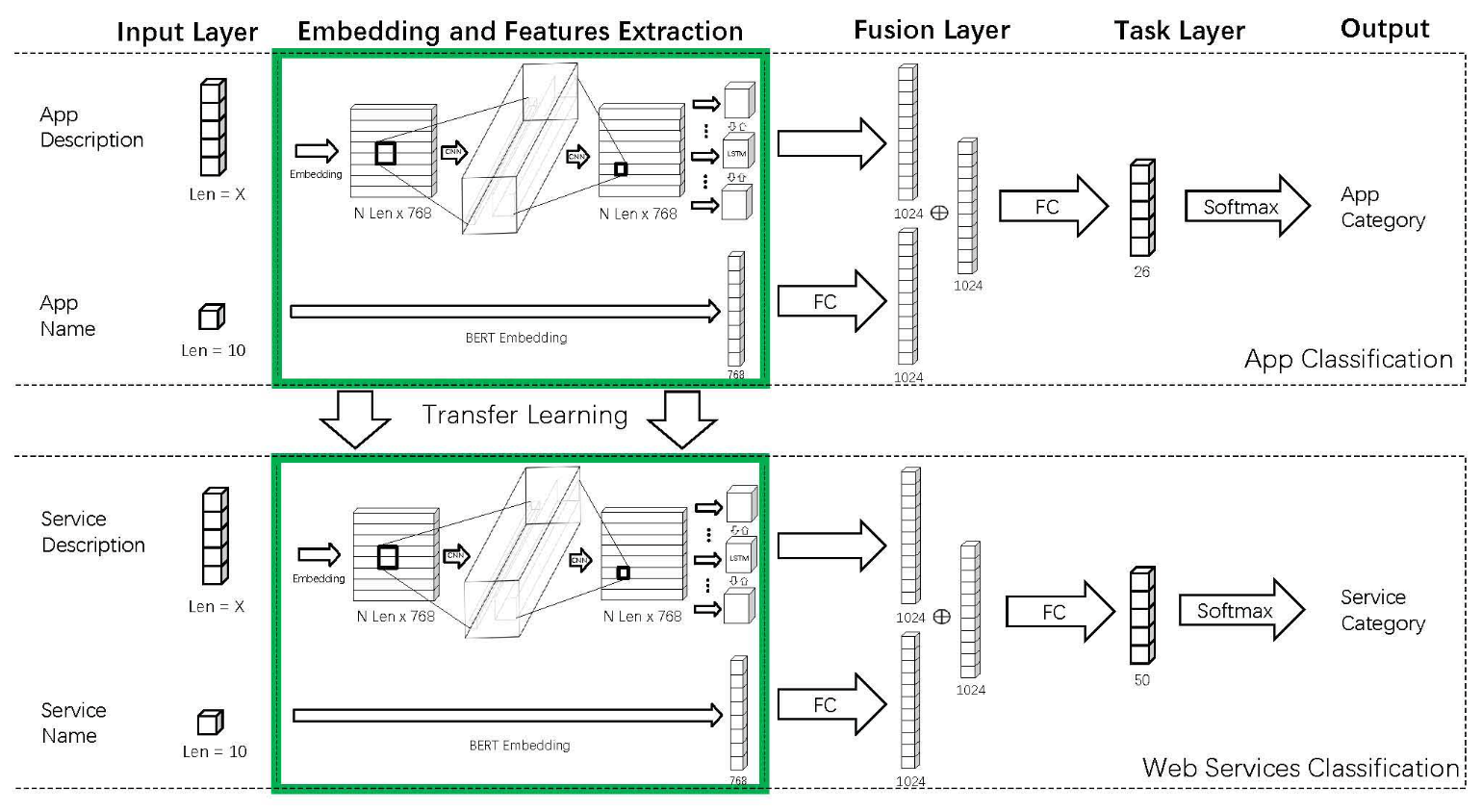 Transfer Learning for Web Services ClassificationYilong Yang, Zhaotian Li, Jing Zhang, and Yang ChenIn IEEE International Conference on Web Services, Oct 2021
Transfer Learning for Web Services ClassificationYilong Yang, Zhaotian Li, Jing Zhang, and Yang ChenIn IEEE International Conference on Web Services, Oct 2021Web service classification is one of the common approaches to discover and reuse services. Machine learning methods are widely used for web service classification. However, due to the limited high-quality services in the public dataset, the state-of-the-art deep learning methods can not achieve high accuracy. In this paper, we propose a transfer learning approach Tr-ServeNet to reuse the knowledge of the App classification problem for web service classification. We pre-train a deep learning model for the App classification problem, in which the dataset contains high-quality data from Apple Store, and then transfer the embedded and extracted features to assist web service classification. To demonstrate the effectiveness of our approach, we compare the proposed method with other existing machine learning methods on the 50-category benchmark with 10, 000 real-world web services. The experimental results indicate that the proposed transfer learning method can reach the highest Top-1 accuracy in the benchmark of service classification.





2020
-
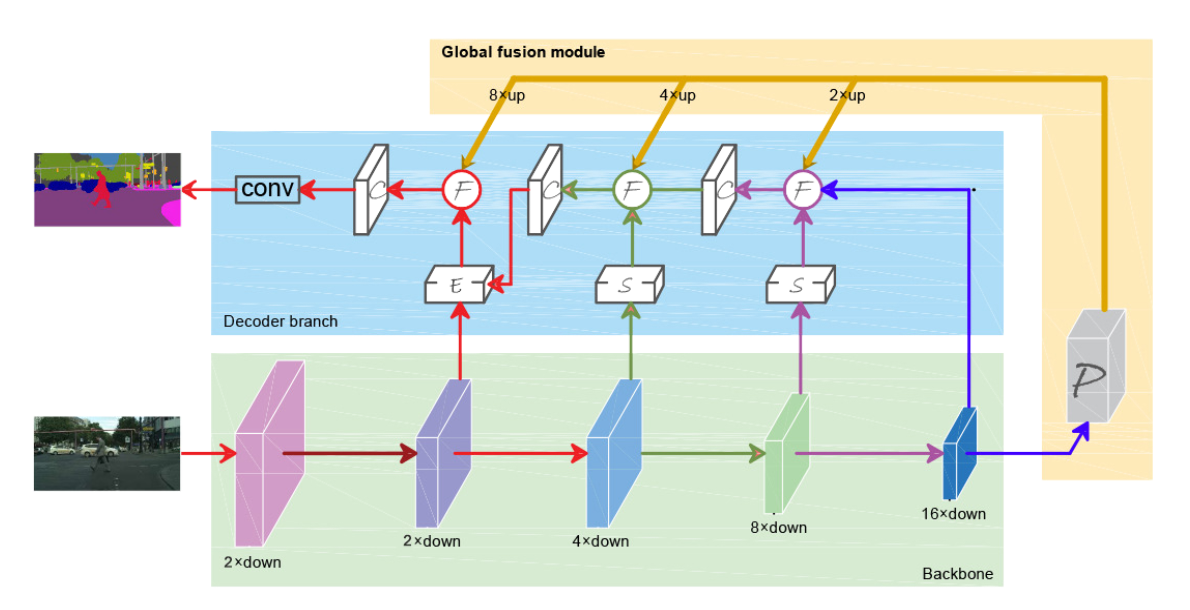 Enhanced feature pyramid network for semantic segmentationMucong Ye, Jingpeng Ouyang, Ge Chen, Jing Zhang, and Xiaogang YuIn International Conference on Pattern Recognition, Oct 2020
Enhanced feature pyramid network for semantic segmentationMucong Ye, Jingpeng Ouyang, Ge Chen, Jing Zhang, and Xiaogang YuIn International Conference on Pattern Recognition, Oct 2020Multi-scale feature fusion has been an effective way for improving the performance of semantic segmentation. However, current methods generally fail to consider the semantic gaps between the shallow (low-level) and deep (high-level) features and thus the fusion methods may not be optimal. In this paper, to address the issues of the semantic gap between the feature from different layers, we propose a unified framework based on the U-shape encoder-decoder architecture, named Enhanced Feature Pyramid Network (EFPN). Specifically, the semantic enhancement module (SEM), edge extraction module (EEM), and context aggregation model (CAM) are incorporated into the decoder network to improve the robustness of the multilevel features aggregation. In addition, a global fusion model (GFM), which in the encoder branch is proposed to capture more semantic information in the deep layers and effectively transmit the high-level semantic features to each layer. Extensive experiments are conducted and the results show that the proposed framework achieves the state-of-the-art results on three public datasets, namely PASCAL VOC 2012, Cityscapes, and PASCAL Context. Furthermore, we also demonstrate that the proposed method is effective for other visual tasks that require frequent fusing features and upsampling.

2019
-
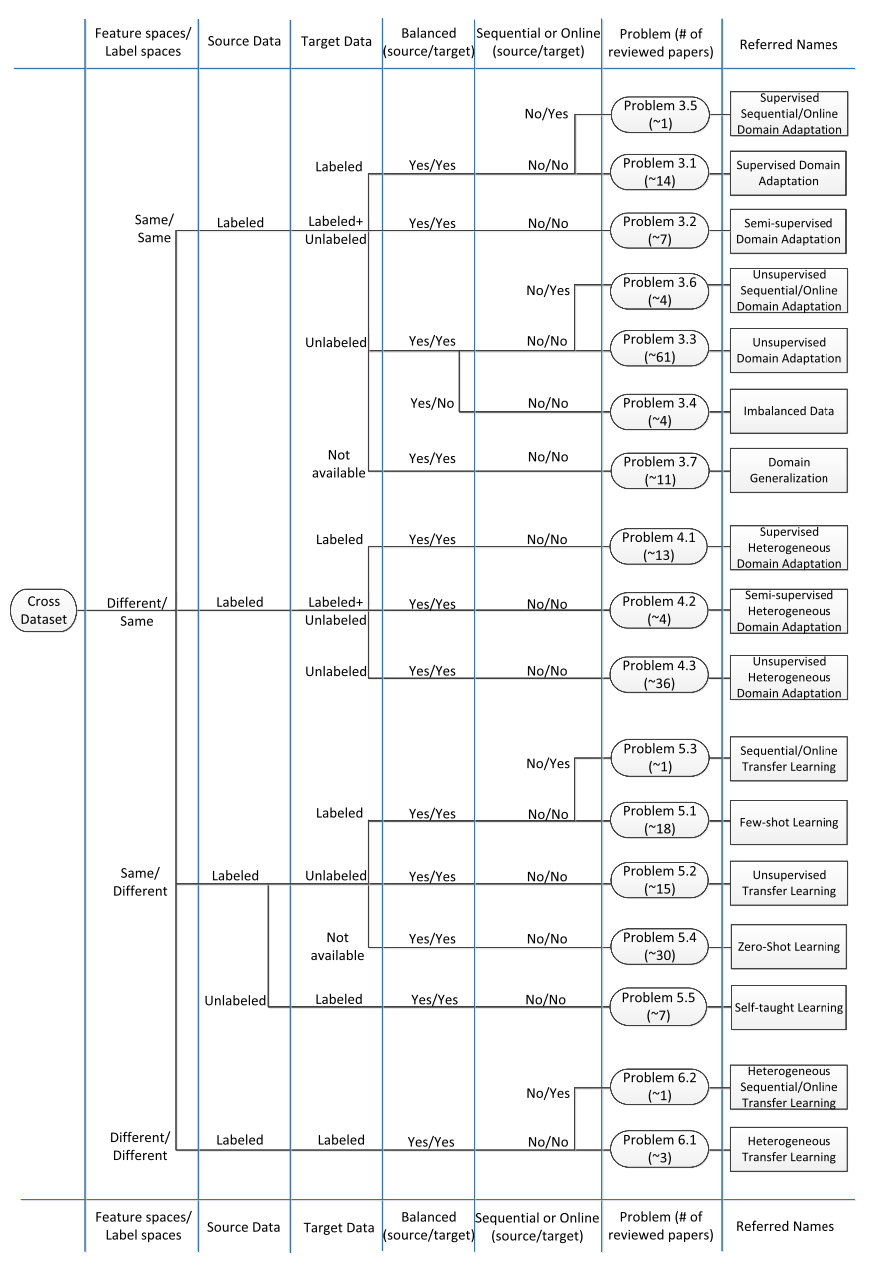 Recent Advances in Transfer Learning for Cross-Dataset Visual Recognition: A Problem-Oriented PerspectiveJing Zhang, Wanqing Li, Philip Ogunbona, and Dong XuACM Computing Surveys (CSUR), Feb 2019
Recent Advances in Transfer Learning for Cross-Dataset Visual Recognition: A Problem-Oriented PerspectiveJing Zhang, Wanqing Li, Philip Ogunbona, and Dong XuACM Computing Surveys (CSUR), Feb 2019This article takes a problem-oriented perspective and presents a comprehensive review of transfer-learning methods, both shallow and deep, for cross-dataset visual recognition. Specifically, it categorises the cross-dataset recognition into 17 problems based on a set of carefully chosen data and label attributes. Such a problem-oriented taxonomy has allowed us to examine how different transfer-learning approaches tackle each problem and how well each problem has been researched to date. The comprehensive problem-oriented review of the advances in transfer learning with respect to the problem has not only revealed the challenges in transfer learning for visual recognition but also the problems (e.g., 8 of the 17 problems) that have been scarcely studied. This survey not only presents an up-to-date technical review for researchers but also a systematic approach and a reference for a machine-learning practitioner to categorise a real problem and to look up for a possible solution accordingly.
-
 Unsupervised domain adaptation: A multi-task learning-based methodJing Zhang, Wanqing Li, and Philip OgunbonaKnowledge-Based Systems, Feb 2019
Unsupervised domain adaptation: A multi-task learning-based methodJing Zhang, Wanqing Li, and Philip OgunbonaKnowledge-Based Systems, Feb 2019This paper presents a new perspective to formulate unsupervised domain adaptation as a multi-task learning problem. This formulation removes the commonly used assumption in the classifier-based adaptation approach that a shared classifier exists for the same task in different domains. Specifically, the source task is to learn a linear classifier from the labelled source data and the target task is to learn a linear transform to cluster the unlabelled target data such that the original target data are mapped to a lower dimensional subspace where the geometric structure is preserved. The two tasks are jointly learned by enforcing the target transformation is close to the source classifier and the class distribution shift between domains is reduced in the meantime. Two novel classifier-based adaptation algorithms are proposed upon the formulation using Regularized Least Squares and Support Vector Machines respectively, in which unshared classifiers between the source and target domains are assumed and jointly learned to effectively deal with large domain shift. Experiments on both synthetic and real-world cross domain recognition tasks have shown that the proposed methods outperform several state-of-the-art unsupervised domain adaptation methods.


2018
-
 A large scale RGB-D dataset for action recognitionJing Zhang, Wanqing Li, Pichao Wang, Philip Ogunbona, Song Liu, and Chang TangFeb 2018
A large scale RGB-D dataset for action recognitionJing Zhang, Wanqing Li, Pichao Wang, Philip Ogunbona, Song Liu, and Chang TangFeb 2018Human activity understanding from RGB-D data has attracted increasing attention since the first work reported in 2010. Over this period, many benchmark datasets have been created to facilitate the development and evaluation of new algorithms. However, the existing datasets are mostly captured in laboratory environment with small number of actions and small variations, which impede the development of higher level algorithms for real world applications. Thus, this paper proposes a large scale dataset along with a set of evaluation protocols. The large dataset is created by combining several existing publicly available datasets and can be expanded easily by adding more datasets. The large dataset is suitable for testing algorithms from different perspectives using the proposed evaluation protocols. Four state-of-the-art algorithms are evaluated on the large combined dataset and the results have verified the limitations of current algorithms and the effectiveness of the large dataset.
-
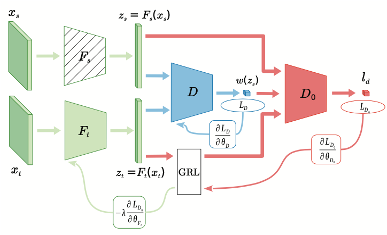 Importance Weighted Adversarial Nets for Partial Domain AdaptationJing Zhang, Zewei Ding, Wanqing Li, and Philip OgunbonaIn Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Feb 2018
Importance Weighted Adversarial Nets for Partial Domain AdaptationJing Zhang, Zewei Ding, Wanqing Li, and Philip OgunbonaIn Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Feb 2018This paper proposes an importance weighted adversarial nets-based method for unsupervised domain adaptation, specific for partial domain adaptation where the target domain has less number of classes compared to the source domain. Previous domain adaptation methods generally assume the identical label spaces, such that reducing the distribution divergence leads to feasible knowledge transfer. However, such an assumption is no longer valid in a more realistic scenario that requires adaptation from a larger and more diverse source domain to a smaller target domain with less number of classes. This paper extends the adversarial nets-based domain adaptation and proposes a novel adversarial nets-based partial domain adaptation method to identify the source samples that are potentially from the outlier classes and, at the same time, reduce the shift of shared classes between domains.


2017
-
 Joint geometrical and statistical alignment for visual domain adaptationJing Zhang, Wanqing Li, and Philip OgunbonaIn IEEE Conference on Computer Vision and Pattern Recognition, Feb 2017
Joint geometrical and statistical alignment for visual domain adaptationJing Zhang, Wanqing Li, and Philip OgunbonaIn IEEE Conference on Computer Vision and Pattern Recognition, Feb 2017This paper presents a novel unsupervised domain adaptation method for cross-domain visual recognition. We propose a unified framework that reduces the shift between domains both statistically and geometrically, referred to as Joint Geometrical and Statistical Alignment (JGSA). Specifically, we learn two coupled projections that project the source domain and target domain data into lowdimensional subspaces where the geometrical shift and distribution shift are reduced simultaneously. The objective function can be solved efficiently in a closed form. Extensive experiments have verified that the proposed method significantly outperforms several state-of-the-art domain adaptation methods on a synthetic dataset and three different real world cross-domain visual recognition tasks.

2016
-
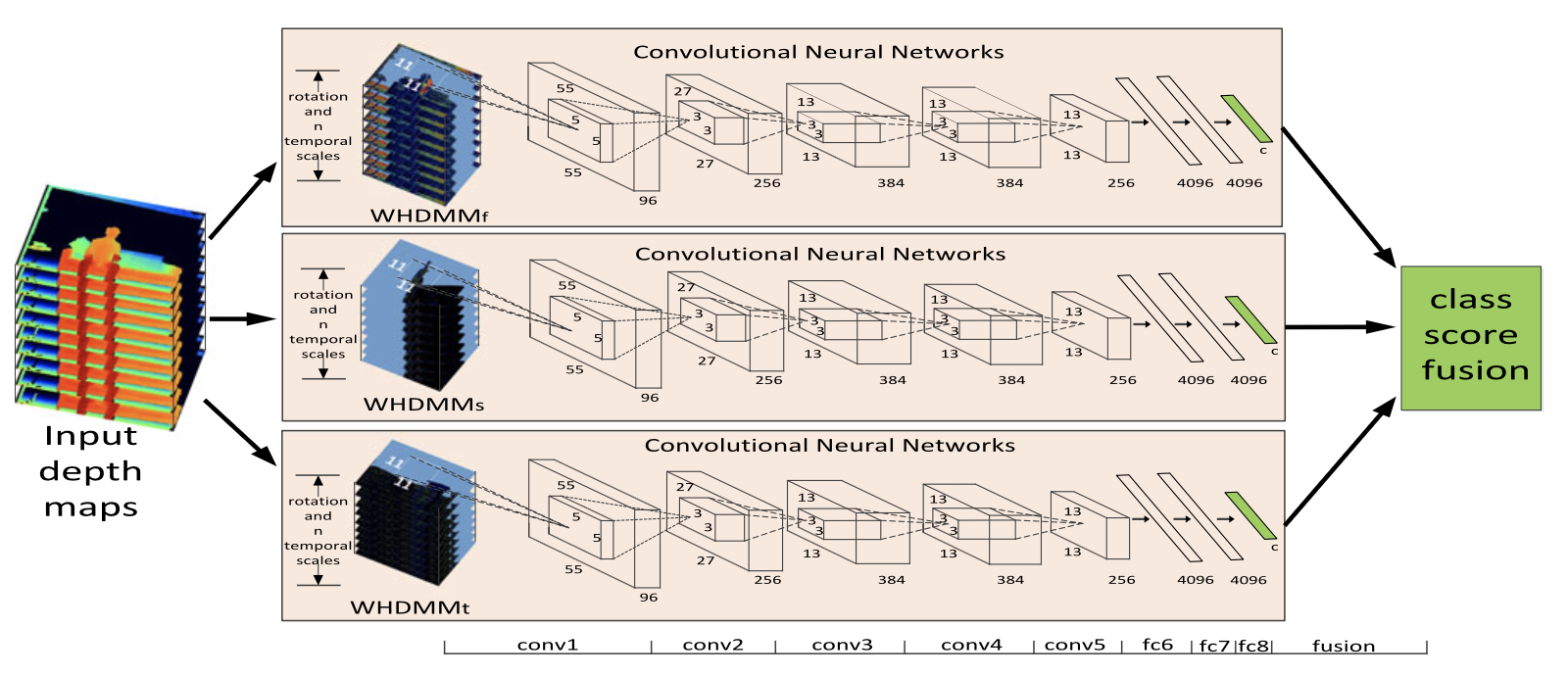 Action Recognition from Depth Maps Using Deep Convolutional Neural NetworksPichao Wang, Wanqing Li, Zhimin Gao, Jing Zhang, Chang Tang, and Philip O. OgunbonaIEEE Transactions on Human-Machine Systems, Feb 2016
Action Recognition from Depth Maps Using Deep Convolutional Neural NetworksPichao Wang, Wanqing Li, Zhimin Gao, Jing Zhang, Chang Tang, and Philip O. OgunbonaIEEE Transactions on Human-Machine Systems, Feb 2016A convolutional neural network (CNN, or ConvNet) is a class of deep neural networks, widely used for analyzing and processing images. Multilayer perceptrons, which we discussed in the previous chapter, usually require fully connected networks, where each neuron in one layer is connected to all neurons in the next layer. Unfortunately, this type of connections inescapably increases the number of weights.
-
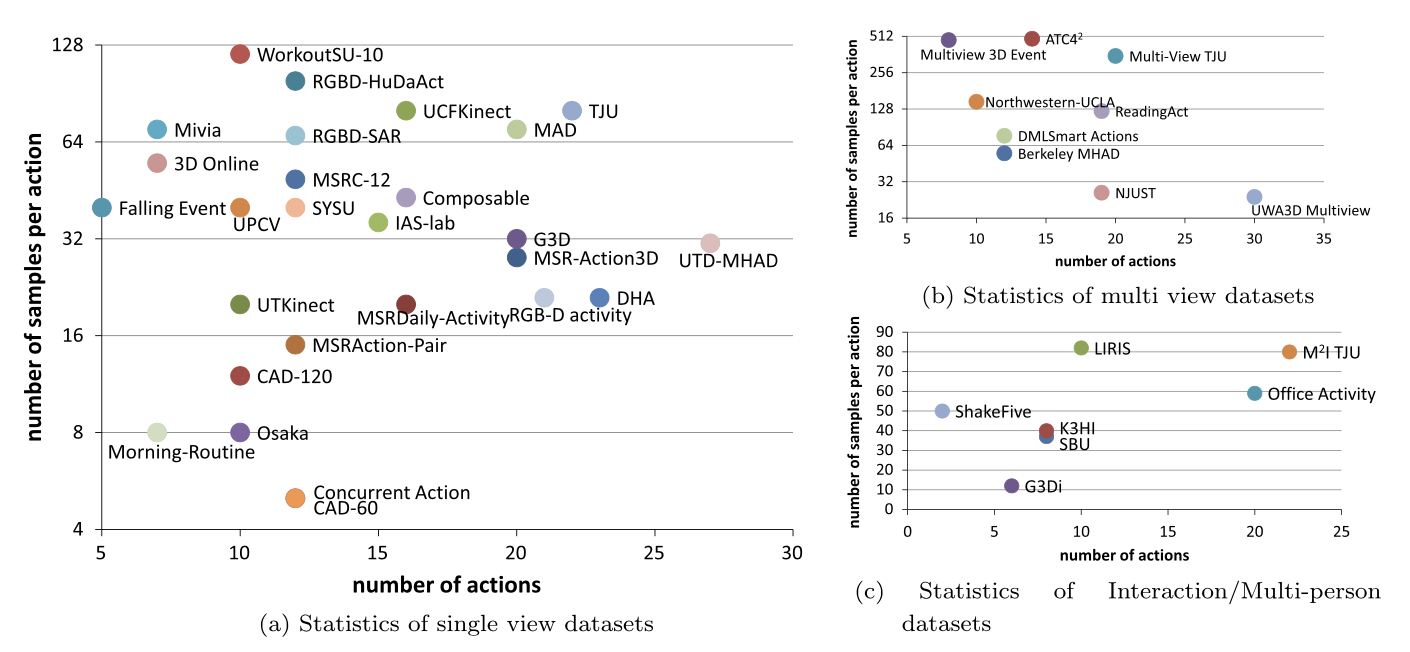 RGB-D-based action recognition datasets: A surveyJing Zhang, Wanqing Li, Philip O. Ogunbona, Pichao Wang, and Chang TangPattern Recognition, Feb 2016
RGB-D-based action recognition datasets: A surveyJing Zhang, Wanqing Li, Philip O. Ogunbona, Pichao Wang, and Chang TangPattern Recognition, Feb 2016Human action recognition from RGB-D (Red, Green, Blue and Depth) data has attracted increasing attention since the first work reported in 2010. Over this period, many benchmark datasets have been created to facilitate the development and evaluation of new algorithms. This raises the question of which dataset to select and how to use it in providing a fair and objective comparative evaluation against state-of-the-art methods. To address this issue, this paper provides a comprehensive review of the most commonly used action recognition related RGB-D video datasets, including 27 single-view datasets, 10 multi-view datasets, and 7 multi-person datasets. The detailed information and analysis of these datasets is a useful resource in guiding insightful selection of datasets for future research. In addition, the issues with current algorithm evaluation vis-á-vis limitations of the available datasets and evaluation protocols are also highlighted; resulting in a number of recommendations for collection of new datasets and use of evaluation protocols.


2015
-
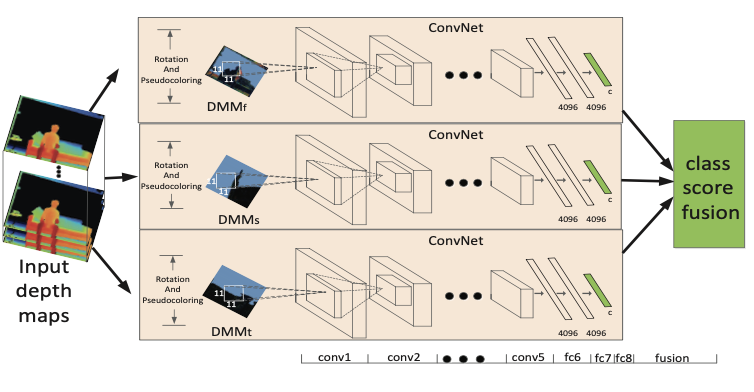 Convnets-based action recognition from depth maps through virtual cameras and pseudocoloringPichao Wang, Wanqing Li, Zhimin Gao, Chang Tang, Jing Zhang, and Philip OgunbonaIn Proceedings of the 2015 ACM Multimedia Conference, Feb 2015
Convnets-based action recognition from depth maps through virtual cameras and pseudocoloringPichao Wang, Wanqing Li, Zhimin Gao, Chang Tang, Jing Zhang, and Philip OgunbonaIn Proceedings of the 2015 ACM Multimedia Conference, Feb 2015In this paper, we propose to adopt ConvNets to recognize human actions from depth maps on relatively small datasets based on Depth Motion Maps (DMMs). In particular, three strategies are developed to effectively leverage the capability of ConvNets in mining discriminative features for recognition. Firstly, different viewpoints are mimicked by rotating virtual cameras around subject represented by the 3D points of the captured depth maps. This not only synthesizes more data from the captured ones, but also makes the trained ConvNets view-Tolerant. Secondly, DMMs are constructed and further enhanced for recognition by encoding them into Pseudo-RGB images, turning the spatial-Temporal motion patterns into textures and edges. Lastly, through transferring learning the models originally trained over ImageNet for image classification, the three ConvNets are trained independently on the colorcoded DMMs constructed in three orthogonal planes. The proposed algorithm was extensively evaluated on MSRAction3D, MSRAction3DExt and UTKinect-Action datasets and achieved the stateof-the-Art results on these datasets.
